goby.garden
goby is a work-in-progress desktop application. this page is inspired by broadsheet, and tracks my live progress through various notetaking contexts. — Nico
Currently I describe goby as an interface for creating and managing personal databases. Compared to existing tools that fall under that umbrella, I want Goby to prioritize things like personal data ownership, durable and transparent file format (SQLite), and referential compatibility with assets stored in different places (desktop files, web URLs, raw text, etc).
goby journal
[src]
12/22/2025
For now I settled for some basic interactions and no motion/transitions. I have single and multi selects displaying and functioning at a basic level
This is kind of working for me12/21/2025

It seems like it helps for the hover state to be in some way directly mapped to where your cursor is, and in this case that also makes it less noticeable when you’re moving between the selections (because the width of the bar is shorter)

12/21/2025
The past couple of days, I’ve been sketching a little on some adjustments to the base presentation and various overlays, some of which are enclosed here. I came up with a few display ideas that I’m excited about, but I don’t think that I’ve cracked the interactions for the selection field yet. I want the table cells to feel reactive to your mouse without attracting an enormous amount of attention to themselves, and I want the transitions in state to feel smooth rather than jarring (but not too slick either). Hover and animations are challenging to prototype as well, because you really have to play with them live to get a sense of how they feel.
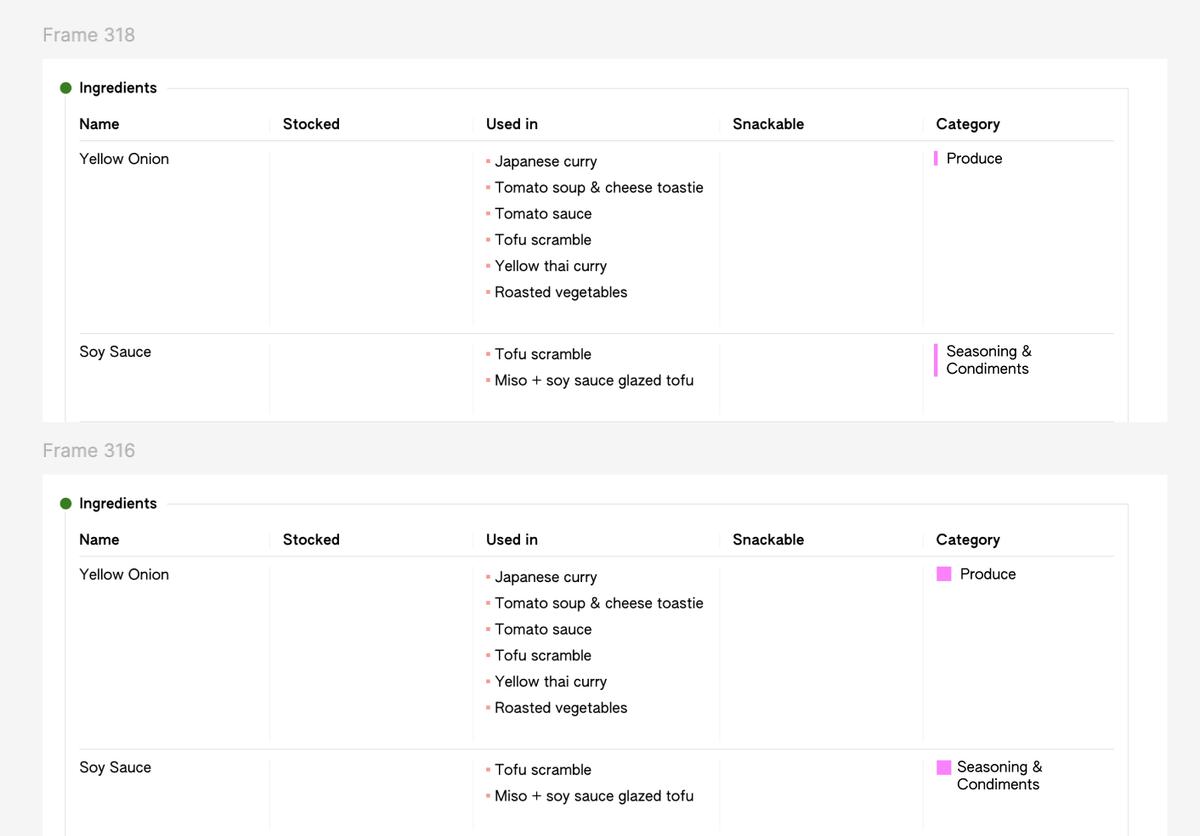
goby-database/notes.md
[src]
Contents:
...and more below
Running notes
12/21/2025
Just a stray thought: I wonder if in the junction tables, I should have the columns for side 1 and 2 automatically sorted by ascending ID number? might considerably simplify my matching functions.
Another stray thought: for cases where a property is matching to itself (same class and prop IDs in both columns), I might need to make a couple adjustments:
- I would need to add some additional suffix to the column names of one “side” in the junction table, like “alt”, in order to prevent duplicate names
- I think the only thing I need to do for the retrieval to work in this case is to make TWO ctes for a single junction table, one matching each side, and then deduplicate somehow for the case where an item is connected to itself.
12/19/2025
As part of my revisit to the select input UI, I’m considering allowing a new item to be added at an arbitrary place in the order for a property, instead of just at the very end, in order to make the cell feel more directly responsive to your click/hover.
The thing is, I don’t currently have a way of customizing the sort order for these items. Previously on 9/1/2025 I added a date_added column to relation junction tables, just to enforce a consistent ordering instead of whatever arbitrary order is produced by SQLite’s inner workings. But I realize this was little more than a band-aid, and there’s something a little uncomfortable to me about encoding such a specific piece of data in Goby’s core architecture, just for the purpose of a display feature.
The eventual goal, as I mentioned then, has long been to figure out some way to support ordered relationships architecturally. And my discomfort with this was that it seemed to require storing the same information in two places (the same relationships, specified within either order). But today I bothered to look up how people ordinarily do ordering of many-to-many relationships, and of course it has a perfectly straightforward solution: just add two columns to the junction tables, using one for the order of the items in one class, and the other for the items of the other class.
It’s a little decentralized, in that you may have relations spread across multiple junction tables for a single item, and the only way to get a full picture of the sequence is to query all the tables together. But there’s no duplication in the way the data is stored.
Once I add this, all relationship properties will in effect be ordered, and by default that will just be the order in which items were added to a selection. This opens up possibilities in the future for a kind of “list”/“hierarchy” display which is based on the contents of a single item relation property.
9/20/2025
Steps to add the filtering feature to retrieve_class_items that I mentioned in the 9/7/2025 entry:
- change the pagination type to add support for conditions
- add
under_property_maxcondition, which takes a relation property ID and makes sure only items which have space to add more selections to the specified property are added
- add
- add the ability to include CTEs for props which aren’t part of the final return (to be used for filtering)
- add a
COUNT()column to the CTE “group by” statements (even if condition is not present), which will count the selections for each item after the unions (surprisingly dead simple!) - modify the
WHEREclause in the outer select to allow multiple conditions besides item_range - when the
under_property_maxcondition is present, add it to theWHEREclause as a comparison of the COUNT column to the max for that prop
(as I am about to push this, I’ve finished all these and the feature is working in my cursory testing)
9/7/2025
Today I added the ability to narrow the output of retrieve_class_items by specific properties as well as specific items, in order to support the “refresh” of data that the interface has determined is out-of-date.
My next agenda item is another feature “ordered up” as it were by goby-interface: the ability to filter the items retrieved by those which still have space in a given relation property to accept more relations. This will be used to display the possible selection options for relation property.
Since I’m not paginating these in the interface right now, I could also more simply include a prop which counts how many selections each item currently has, and then filter by max value in the interface. but this is elaborate enough that I figure I should just go ahead and figure out how to do it the right way, filtering directly in the SQLite query.
To do this, I think retrieve_class_items is going to have to accept a list of conditions (the first of which will be this “property can accept more values” condition), and handle them each in a custom way. This will require adding custom computed columns to the select, and additional WHERE rule that evaluate the computed columns. In the case of this first condition:
- a custom computed column, reusing a lot of my existing relation/junction table logic, to count the items selected for a given property instead of listing and formatting them as json.
- a WHERE rule which checks if the computed column is below the max for the property.
9/1/2025
Some scattered thoughts as I’m working today:
I’ve reached a point where I can save new relationships back to a project database, and I’m noticing that when I reload, the sort order of the item I just added changes. After looking it up, I’ve realized that using a left join without specifying order results in an indeterminate ordering, apparently based on what the query optimizer decides is the best way to order stuff.
The customization of relation sort order is a larger technical challenge that I may have to tackle at some point. It sort of contradicts the whole point of the junction table approach by necessitating that data be stored twice or more (to specify the order on each property participating in a relationship).
But for now I think a simple thing I can do is just add a date_added timestamp column to my junction tables, and specify that this be used to sort relations, that way it will privilage recency.
To maintain my sanity in the front-end (and probably also for general consistency) I need to either make the slim return of items use id instead of system_id, or make the array of selected items for a relation prop use system_id instead of id.
6/23/2025
Following my last goby-interface note, I’m removing all references to the item cache, which is pretty easy because it wasn’t really doing anything yet.
The thing I will need to do in its stead now is modify my class/workspace retrieval functions to manually pull the items for the classes I need, since I was previously relying on automatic caching filling in the items when I fetched them. So a few steps (to do in reverse order):
- change
retrieve_workspace_contentsto retrieve all class metadata instead of a subset, and do it withretrieve_all_classesinstead of the cache.- instead request just a subset of items, i.e. the ones for the classes which appear as blocks.
- modify
retrieve_all_classesto take a parameter which specifies which items to fetch for each class (if any). Then useretrieve_class_itemsto populate the items when requested. This will be the foundation for pagination. But for now I can just set the range tonullso it fetches all the class items when requested. - modify
retrieve_class_itemsto accept a pagination range (ornullfor all items as mentioned, and later on I can actually implement the pagination). - modify the
itemsproperty of theClassDatatype to record the pagination state in addition to the actual array of items.- should include an attribute for the range of items fetched (page size, page #, sort order), and also a attribute for the columns/properties, which can either be a list of IDs or a generalized string setting like "all" or "slim"
- this will obviously have trickle effects to the interface. luckily with typescript, all the errors that this change generates should bubble up as type errors in my code editor.
6/22/2025
Today I’m working on rendering the selection fields in the interface (we’ll see how far I’m able to get!). I realized that my class item retrieval function doesn’t return any information about relation property values beyond the class and item IDs of selected rows, i.e. the minimal information to identify them. My first thought was that I could add a helper function that just returns all of the possible options for a relation prop, since that will be needed anyway for the dropdown fields. But I still have a dream of this library being useful as a standalone API to interact with goby databases, and to that end I think that the item retrieval function should probably be a tad more robust in its return value. Not that it should return the full item, but I think it should have enough information to display a list of selected items.
This gets me to a feature which I’ve envisioned including for a long time: a ”label” attribute, indicating which property of a class should be used as the signifier for its items in more abbreviated displays.
One thing that I will have to sort out, and recall dealing with in the initial implementation of all this, is what happens when the label value is empty for an item? How should it display as an ”option”? I may have a more robust answer to this later on, but for now I think I will just filter these out in the option list. In the “selected” option display, maybe I will let these remain, but just show the item ID.
Another question is where to store the information about which property is the label. One possibility is storing it in the property table as an SQLite column on the property itself. This appeals to me because I’ve been trying to move away from encoding data in stringified JSON. I could also store it as a foreign key column in the class registry, e.g.
label_property(actually, I suppose I couldn’t do it as a foreign key because properties have their own per class tables). Lastly I could store it as alabelkey in the metadata JSON for the class. Despite this not having the advantages of normalization and possible SQLite-native validation, I think this is actually an attribute that I may want to be mutable. For example in the future I could want to add the ability to concatenate multiple properties into a label, so that people can add things like emoji/icons and possibly even image thumbnails. So in conclusion of this thought, I’m inclined to go this latter direction.
Note to self upon exploring the foreign key idea: with any current and future foreign keys, I should consider how to handle deleting referenced items, given SQLite’s default behavior and possibly useful behavior options.
Aside from this change to the return of relation properties, I will also need to change the item retrieval function to support retrieving all the options, as I mentioned. For that I want to add a paremeter which basically pares down the return value to just item ID and label.
4/13/2025
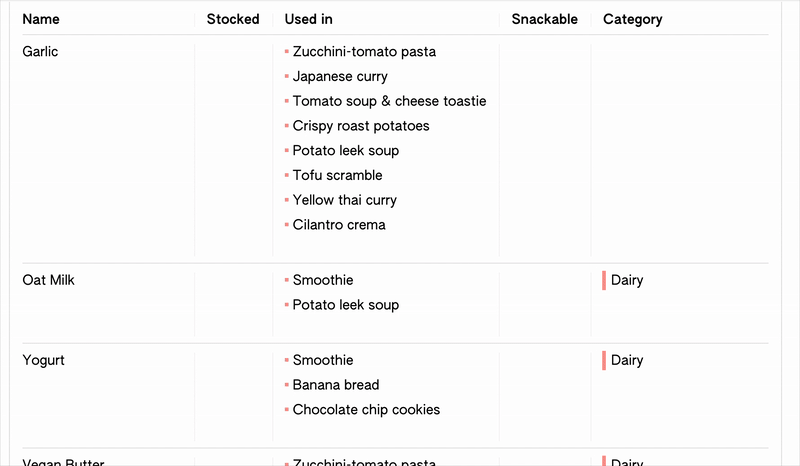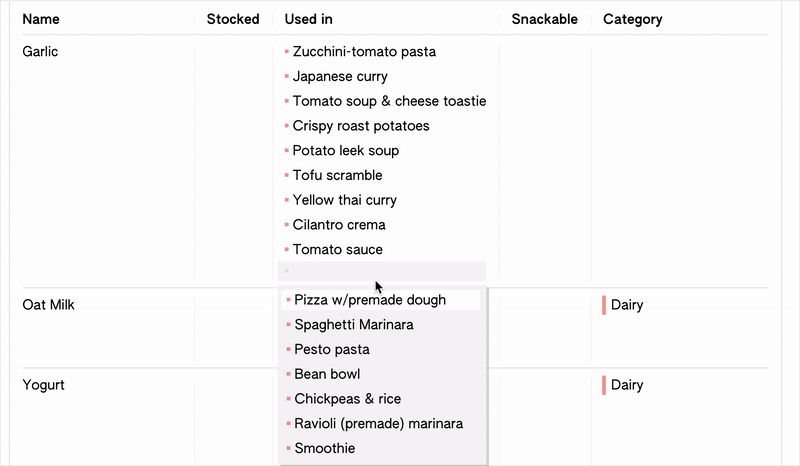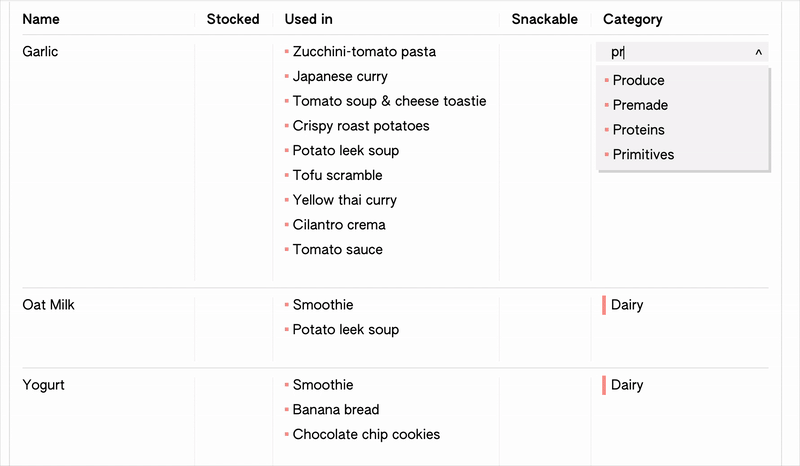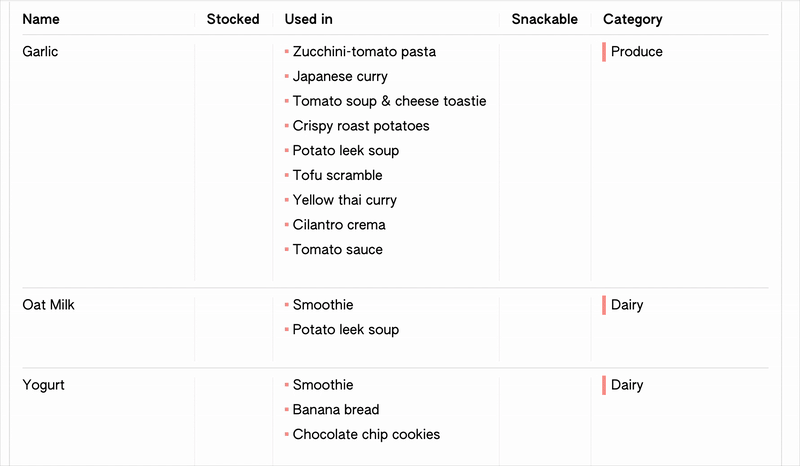
I’m working on creating a sample “groceries” project to develop the interface with, using a dataset I assembled of our typical recipes and grocery list. As ever, working with test data is challenging my assumptions about what the editor should be able to accomodate: I have two properties in my recipes table, “ingredients”, and “nice-to-have”, which both reference my “ingredients” table. Then in the ingredients table, I have a ”used by” property, which you would expect to be linked to both of these recipe props. However, this isn’t allowed by my schema editing function (which happily my error-catching prevented), because although it would be mostly doable structurally, it would be difficult to resolve in the interface. I.e. when you opened the dropdown to select recipes for "used by", there would be no default way of specifying or knowing if it would make a relation with the "ingredients" or the "nice-to-have" property in Recipes.
I think I’m fine with this limitation for now, though in the future it could be worth enabling it and thinking about how it would be resolved by the interface. Maybe it could be based on priority, like when creating the relationships I would set it so that when selecting from the ingredients side, it would always reflect the changes in the ingredients prop rather than used by. I would also need to account for multiple properties in a row selecting the same item, in which case I (probably?) wouldn’t want to list a single item twice.
1/18/2025
Picking up on the reflection from the 16th: I’ve taken care of cases where transfers get queued for nonexistent targets, and general duplicate actions, by filtering those out in the consolidation step. The open question is what to do when someone deletes a property which was previously a target, and then adds their own new target within the same class. Normally when you delete a property which was a target, I queue the creation of a one-way relation to replace it, and transfer the connections from the previous two-way.
It’s an open question whether to keep that behavior at all, since I could imagine the function just deleting everything that involves deleted targets, with no attempts at preserving data. Likely the interface will automatically handle some of this anyway, and send an input that takes it into account. But on the other hand I think it is nice, especially if someone uses the class as a programmatic interface (not that I necessarily see that happening, but maybe if this project miraculously takes off). So I think I’ll leave it in, and in the future what I could do is make that an option, e.g. "safe mode", set to true/false, that way you can bypass it if you prefer.
What I’d like to do though, since this problem is about validation with other relationship edits, is to address it in the consolidation function. And I think I have a way to accomplish that: when consolidating, if there are multiple creations/transfers involving the same pair of classes and one matching property, pick the one with the highest level of specificity, meaning privilege prop targets to class targets.
1/16/2025
- I think I need to modify my logic for deleting or creating relations on the basis of classes/properties being deleted
- e.g. if I delete a property, but rather than targeting the whole class, I already have a change queued to move the target to a different property. In that situation, it should honor what’s already in the queue instead of queing or overriding another transfer
- also, what happens if the classes on either side of a relation are deleted? there may technically be available transfers individually, but they cancel each other out. I need to make sure the classes and properties in new_sides, exist, otherwise reject a transfer and just delete.
1/13/2025
Current to-do:
- refactor junctions so that:
- in the junction list, the following are normalized: side_a_class_id, side_a_prop_id, side_b_class_id, side_b_prop_id
- should be retrieved as a JunctionSides json array
- in individual junctions, the columns should be a little more descriptive, e.g. class_2_property_5 or class_3
- in the junction list, the following are normalized: side_a_class_id, side_a_prop_id, side_b_class_id, side_b_prop_id
- refactor properties so they exist in their own tables, and are created when classes are created
- refactor class/junction retrieval and caching
- reflect above changes
- separate retrieval of items, properties, and relations
- get relation targets from junction list rather than storing them on the property (DRY)
- implement junction transfer
- take a pass at unifying/clarifying the terminology a little bit
- maybe replace "junction" with "relationship" and "relation" with "connection"?
Currently working through revising the edit schema function. The class and prop edit loops were simple enough but the relationship edits introduce some complexity:
- relationships can be one-way (e.g. class A prop 1 -> class B) or two-way (e.g. class A prop 1 <-> class B prop 2)
- if a two-way is converted to a one-way, or vice versa (i.e., when both of the classes and at least one of the properties persist) we want to transfer the old connections to the new relationship, instead of deleting entirely.
- I should also enforce the rule that a property can only target one property from a class
How to handle this? What I’m thinking:
- create a new consolidated edits array
- add the type:"transfer" relations to the array
- loop through type:"create" relations
- check if there’s an existing relation that matches both classes and one property
- if it exists:
- look for a type:"delete" which deletes this relation
- if there’s a delete, push a transfer
- if there’s not a delete, ignore this creation because it’s invalid
- look for a type:"delete" which deletes this relation
- if it does not exist
- add the type:"create" normally
- if it exists:
- check if there’s an existing relation that matches both classes and one property
- loop through the type:"delete" relations
- check if there’s already a transfer for it in the consolidated array, and ignore if so
- loop through the consolidated edits array and apply the changes
1/7/2025
the current dilemma is an empty selection is showing up for
FROMin the class retrieval SQL query, causing a syntax error. I’ve isolated the problem to be that in the sandbox file, I’m attempting to create a relation property without specifying targets, although the property implicitly has some targets, just based on the junctions I’m declaring in the sameaction_edit_class_schemacall. So there are a few dimensions here:I want to figure out why my type definitions for the input to that function aren’t flagging that there should be
relation_targetsfor properties being createdI need an approach to relation props that do not have any targets. I don’t necessarily want to allow someone to create them manually, but if all the targeted classes gets deleted, I need a way of handling that which does not break things. Here is my inclination:
In the interface, warn you if your changes will result in a relation property without any targets. Allow them to do it though, because I know it would be annoying to have to go through editing every property which depends on a class before deleting the class itself.
Conditionally handle empty relation props in the class retrieval function by making them return an empty array instead of it breaking by trying select out of nonexistent SQL tables
I wonder at what stage I should be performing validation for synchronicity between the junctions and the classes being created. There have sort of been two schools of thought I’ve been bouncing between while building
action_edit_class_schema:- goby-interface will regardless have to implement a way of on-the-fly editing the staged schema in concert with the GUI, so the input that this function will be getting programmatically should be correct.
- However, I may want to expose this function for developers to use outside of the goby-interface environment, and it should be modular and stable enough to not crash the database if you fuck something up (such as the error I’m encountering in my sandbox). Part of that is just doing type-checking to prevent malformed inputs, which would resolve my current issue, but part of it is making sure the input is logically consistent.
Right now there is a level of redundancy involved, in that I’m specifying both a list of changes to classes, which include some of the relationships which are specified by the junction list. I think in an earlier incarnation of this function, assuming I set it up correctly (which without types is a little iffy to me), it may have been able to infer the targets from the junctions. In any case there’s not an exact parity between the two arrays, such that I could inversely infer the whole junction list directly from the list of changes to classes, because it is the whole junction list: a list of every relationship that is recorded by the project database. Then there’s action_update_relations, which is independently performing validation and figuring out what SQL changes need to be made by simply comparing the current and staged lists of junctions.
I think I wanted to pass the whole junction list because that’s way easier from the side of the interface. I will likely have the junctions separated into their own array rather than only implicitly contained in the properties, because that’s a convenient way to represent the data and because it prevents me from having to fetch the whole schema of every class. Then in the editing mode, instead of recording each edit to the relations, I would just need to record the new holistic state and give it to my code here to deal with it. But if I’m doing diffing somewhere anyway, I might as well handle that logic on the front-end, or even provide myself with some utility functions via this package to do it there.
In terms of what actually makes sense to pass to action_edit_class_schema, I think I ought to only include the class array, and compile a list of resulting junction changes. What does this entail in terms of handling?
- For property creation: simple enough, create new junctions for each of the targets of the new property
- For class creation: no need to do anything unless a relation property is also created
- For class deletion: delete all the relations which involve this class (see discussion above of empty relations)
- For property deletion: delete any junction tables for one-way class targets of this property. For two-way property targets, instead of completely deleting the tables, I want to convert them to represent one-way class targets by the surviving property
- For property modification: if the targets change, I just need to create or delete the corresponding tables
This precipitates the realization that another thing that I will have to infer somewhere is what properties will have to be changed as a result of explicitly editing others. Namely, targets will need to be added or removed to corresponding classes based on the changes I make.
It also precipitates the realization that it will be difficult to conclude what changes I need to execute while looping over the change list, since changes may override each other (e.g. I don’t have to delete a property on a class if later on in the edit queue I’m deleting the class altogether). This is probably why I thought to pass the complete new state of the schema rather than a list of edits.
How about this - instead of consolidating the representation of the edit into one list, maybe I differentiate it more:
- List of class creations and deletions, and title/metadata edits
- List of on-property changes, like deletion/creation, data types, and title or styling
- explicitly does NOT include targets. they will be populated in 3.
- List of relation changes, like changing the targets of the properties
- does NOT include changes implied by class and property deletion. these will be inferred and added when processing #1 and #2
- DOES include uncreated properties from #2. When going through those changes
This will accomplish a few things:
- normalize the changes into different categories
- establish an order of operations which prevents changes going through that counteract/override each other
- each step depends to a certain extend on the ones that come before it. e.g. properties of a new class need the ID of the class registered before they are created, and new relationships need the IDs of newly created properties (and classes) in order to be themselves registered.
- prevent information redundancy in the parameters, and the need as a developer to explicitly detail all of the implications of the change that I’m making
- create a validation funnel for any change to the schema; since every change goes through this function, it can be the central location for any validation logic, and you can make either isolated or bulk changes, which are always handled through the same stable procedure
It has one notable drawback:
- I have to create data property columns through ALTER TABLE rather than defining them with their class. But I might have been doing this already? (yes, I am already doing this)
Another separate thing that occurs to me, which may be a way of solving the current error without philosophical ponderings, is that what’s actually causing the error is me trying to retrieve the items in a class mid-way through editing the schema, because I call refresh_class_cache during the class/property creation process. I think this is either an oversight from when I was last working on this, or an oversight from the past couple days of converting to typescript. I should have two functions:
- One that refreshes the list of classes (with IDs, titles, metadata), and each of their schemas.
- One that refreshes the list of items for each of the classes fetched by #1, populating the items array which will be created, empty, in #1.
So in #1, the other thing I will need to do is search the cache before I replace the array to see if that class is already recorded, and copy over the items from the old ClassData object to the new one.
Other random thoughts:
- maybe I should replace "metadata" everywhere with "attributes"
- maybe rename PropertyDefinition to PropertyConfiguration or PropertyConfig
- could I hypothetically add order to relations? just via an order column in junction tables?
- I do not think so, because the order would be different for each item
- but I could potentially add the order as an array of IDs in the property metadata? this would just require a dreaded maneuver, storing the data in multiple places...
- it could be a JSON column in junction tables keyed by class and prop... but that does sound like a Pain to manage
- could I hypothetically use one-to-many columns in the global table of junctions that identify them with properties and/or classes?
I don’t know if this would implicitly accomplish the above BUT could I just normalize the class and prop IDs in the junction list like so?:
| id INTEGER NOT NULL PRIMARY KEY | side_a_class_id INTEGER | side_a_prop_id INTEGER | side_b_class_id INTEGER | side_b_prop_id INTEGER |
FOREIGN KEY(side_a_class_id) REFERENCES system_classlist(id)
FOREIGN KEY(side_b_class_id) REFERENCES system_classlist(id)
I guess I have to decide whether to create a global properties table as well, just like objects, which could be the foreign key reference for the property ids.
- or... do I create a global table for class and prop IDs, such that I can just have side_a and side_b referencing IDs in that table, whether they are classes or properties (okay that might be slightly unhinged)
Goby technical terminology:
Some rough definitions of the terms that I use in the goby-database codebase*.
Conceptual architecture:
item:- an entity possessing
properties - can either be independent
- represented as a free-floating
blockon aworkspacecanvas
- represented as a free-floating
- ...or belong to a
class, inheriting the properties it has from saidclass- represented as a row in a table
- an entity possessing
class:- the declaration of a kind of
item, with a user-defined set of properties. - represented as a table, which contains all the items belonging to a class
- the declaration of a kind of
property:- some user-defined quality of an
item, e.g. the title, page length, or genre of a book - two kinds:
“data” property: any kind of raw data, i.e. a string of text, a url, a file path, an image, a number, a data, etcetera.“relation” property: a kind ofconnectiondrawn between items in the database.- For example, an “author” property of books which references items in the “author” class.
- It may involve
relationsto multiple different classes/+properties
- some user-defined quality of an
connection:- a link of some kind between two
items
- a link of some kind between two
relation:- the declaration of a kind of
connectionexisting betweenitems, mediated through their properties.- For example, in a parent-child relationship, the "parents" property in a child would be linked to the "children" property in a parent
relationis toconnectionasclassis toitem- a
junctionis the technical component in SQL by whichconnectionsbelonging to a givenrelationare recorded in the database
- the declaration of a kind of
Visual architecture:
workspace:- a gridded, spatial canvas on which
itemsandclassescan be represented and edited visually as rectangular cells of mainly text content.
- a gridded, spatial canvas on which
block:- a discrete object placed somewhere within a workspace
- typically the visual representation of an
itemorclass(and its members)
*Unfortunately for now I can’t compose the definitions without resorting to some level of jargon, loosely pulled from my education in philosophy and logic, as well as some level of circularity, owing to the way these terms are constitued by their relation to other terms.
Things this program should be able to do:
initialization
- check if system tables exist, if not, create:
- root object (rows/cells) table that generates/records their unique ID
- junction table for individual relations
- class list
- junction table list
- image data table for all image data, referenced elsewhere by file name
- check if system tables exist, if not, create:
user actions:
- create a class
- define properties on classes
- static data
- relations
- create and/or modify the participant classes
- create and/or modify the junction table
- create objects in classes
- enter data for property
- undo anything (can this be achieved? see Implementing undo/redo below)
- sqlite has a page detailing a method for achieving this
- importing data
- csv to class
- ability to convert columns into relations by text-matching
utilities:
- create a table
- core system tables
- user-defined class tables (recording members of a class and their static properties)
- junction tables (recording defined relations between classes)
- create a table
data retrieval:
- retrieving data related to classes or objects in json form
- pagination-friendly
validation:
- changing column type
- from multiple to single
- int to string and back
- defining new relations
- making sure objects on the single-select side of a relation aren't added to multiple objects in another class
- class-to-self relations
- deleting rows, columns, and classes
- for relational properties, the related class should have the option of dropping their column, converting to a string, or (if they're connected to other existing classes) just removing those relations
- changing column type
Stored data
- class metadata:
- functional:
- properties
- type
- junction ID if relevant
- property ID
- styling: order, whether or not it displays, its column width
- properties
- styling:
- the property it uses as a label (default:name)
- its color
- functional:
Core concepts:
- relations types are a unit, embodied by a junction table
- they define a type of property, shared across its constituent classes
Junction tables (how relations work in goby)
- the targeting problem in the old system(see ref):
- when you make a relation, you can pick multiple targets. the question is: can those targets have each other as possible relations? in other words, can that junction table host relationships not involving the class on which the junction was initiated?
- the resolution:
- an overhaul of the way relations are stored and structured, so that it all around makes more sense and isn't arbitrarily tied to the shape of a big junction table (see next bullet)
- the new system:
- when you make a relation property, you pick targets like before
- you can just pick a class as a target, in which case it's one-way, or you can additionally specify a property in a targeted class to link it with
- The big change here is that properties can specify which targets they link with, rather than having to be "linked" across the board (which didn't make much sense anyway). And they can target any set of classes/link with any property as long as they follow a common sense rule:
- the basic rule governing possible relationships is that a property can only be linked to one property from a class
- however, that one property can be itself
- Q: can two properties within the same class be linked to each other?
- A: Yes. Imagine "parent of" and "child of" properties.
- Q: what happens if you start with a class_1.property_A targeting class_2 without any link, and decide to link it with class_2.property B ?
- I would transfer any unlinked relations from class_1.property_A to this new link, along with any unlinked relations from class_2.property_B which target class_1
- only caveat is I would validate the relations to make sure they don't violate any constraints on either property, e.g. class_1.property_A having a limit of 1 relation per object
- the technical implementation: individual junction tables
- rather than have a single junction table for all of the targets of a property, I'm going to have one junction table for each target. It will have just two columns, one for each class/class.property.
- following the rule above, the only condition is there can only be one junction table for a class.property and another class
- junctionlist structure:
| id | classA_id.propA_id | classA_id.propA_id | metadata? | - each junction structure:
| classA_id.propA_id | classB_id.propB_id |`
- rather than have a single junction table for all of the targets of a property, I'm going to have one junction table for each target. It will have just two columns, one for each class/class.property.
- maybe "count" could be generalized to a "max" condition?
- although maybe in the interface still making it a toggle between the single and multi-select that people are familiar with
- this doesn't work because the conditions are supposed to determine candidates for a relation, and if this is a condition then a single select will have no candidates
Return format for relation properties:
- for each row, an array of the objects its connected to, in the format:
{class_id:X,prop_id:X,object_id:X}
Structure of SQL request including relation prop structured as JSON array
WITH cte AS (SELECT person, ('[' || GROUP_CONCAT(clothing,',') || ']') AS clothing
FROM (
SELECT person, json_object('type','shirt','id',shirts) AS clothing
FROM junction_shirts
UNION
SELECT person, json_object('type','pant','id',pants) AS clothing
FROM junction_pants
UNION
SELECT person, json_object('type','shoe','id',shoes) AS clothing
FROM junction_shoes)
GROUP BY person)
SELECT p.id, p.name, c.clothing
FROM people p LEFT JOIN cte c
ON c.person = p.id;
Window management
After some considerations about how windows will work in Goby, I’m moving forward with the idea of having the database file store information about windows in a separate table.
Here is what I’m thinking for the table structure:
window ID #type:home/hopper/ orworkspace- I’m thinking that there will only be one
homewindow and onehopperwindow, added during the init process as IDs #1 and #2 in the table
- I’m thinking that there will only be one
open:true/false- goby will iterate over this and check if it has to open anything
metadata:{json}.position(on desktop):[x,y].dimensions:[w,h].type: (for workspaces)canvas/focus.items:(for workspaces)[array of objects and tables in this view and their styling meta].position(in window):[x,y]- other styling TBD...
Names versus IDs:
- One goal is to make the sql database on its own somewhat legible
- However, without care, names will run amuck and renaming something will require changing the name in a thousand places.
- Current approach to this for classes and properties is have their names on the actual tables and columns, and their IDs in places where metadata for classes is stored, so at most you only need to change their name in two places
Development thoughts:
the idea is this package will be imported as a module into the application
possibly will make it a cli before i make it a gui
for class retrieval, possibly create a custom aggregate function
all user input functions begin with "action" and
Misplaced interface thoughts:
- relation-select reactivity: instead of some array-copying madness, just have the selector set to the current items as an event, fired with every data update
- editing relations:
- I think I'm going to narrow from the previous iteration of the relation creator/editor so you can only configure one relation at a time, meaning you can't edit the constraints on the other relations
- since a system-wide undo/redo could be quite difficult to implement, an alternative could be using transactions, so after making a change, particularly a table structure change, you would be prompted to commit or reject changes
- MAYBE there could even be an enterable "transaction mode", in which you make a variety of changes, and then make a decision about whether to accept or reject them.
Misplaced general organization thoughts:
- maybe the website can have a kind of "timeline" pulling in the goby are.na channels using the api, letting you drag a slider to move forward/backward in the notes i take about it, which appear as a scattered collage
Implementing undo/redo
- This isn’t top of agenda for me right now because it’s really complicated, and based on my current understanding it shouldn’t be too tricky to build into the codebase later on.
- Undo/redo functionality isn’t built into SQLite, but they do detail a way of technically achieving it here. I don’t fully understand how it works yet.
- I think a simple first goal, when I do get to this, would be to implement undo/redo when it comes to simple data entry, i.e. changing table cells or adding/deleting entire rows.
- Where I’m anticipating this will get messy is when it comes to Goby’s class design, which allows you to design your own table schema. Undoing/redoing changes to table schema is a more complicated thing which probably isn’t accounted for in the customary approach linked above.
- Moreover, I’m expecting that simple changes like adding an object to a class or changing item styling will be the typical use cases for Command-Z functionality.
- For class design, I can take advantage of SQLite transactions to provide a brute force way of letting you discard all changes and roll back to a saved state. Maybe the interface can give you some way of “committing” changes, or a way of entering “transaction mode”
- Another thing to consider/look into: is there a way I could integrate this with git somehow, and have a sort of brute-force undo-redo powered by rolling back changes at the raw data level? Reminds me of that thing that happens when you open an indesign file and get a second, temporary file. Could I somehow track changes while you work and live commit them?
Commands
With my new typescript and package export setup I have some new commands for development, which maybe I ought to record here:
npm run build: runs the typescript compiler on all the files insrc, adding them todist.npm run test [test name]: this is my system for putting all my tests in one file,sandbox.ts, and passing in a string parameter with the name of the test to run. My tests so far:in-memory: some general tests of goby’s schema editing capabilities in an in-memory databasegroceries: this generates a timestamped project file with recipe and ingredient classes. I’ve been using this test and exporting the file to use as the foundation for my interface developmentgrocery-queries: starts with generating the groceries project but only in memory, and then does some validation tests workign with a substantive data setunit-relation-matching: my first “unit test”, verifying that one of my more complex utility functions returns expected outputs in a variety of scenarios.
Test suite checklist
Basic:
- create a class
- delete a class
- deal with relation fall-out
- add a row to a class
- delete a row from a class
- deal with relation fall-out
- add a data property to a class
- delete a property from a class
- not allowed if class only has one property
- deal with fallout if that class is the label
Relation properties — test the following actions/options in relevant combinations with each other:
- adding a new relation prop
- setting the
conditions.max(formerlycount) and validating relations correspondingly - deleting a relation prop
- linking a relation prop to another prop, new or existing
- having a property target its own parent class
- removing a link between two props
- adding a new relation
Returning data:
- return relation props in the format specified in Return format for relation properties
Workspaces in the database
- columns in a generated workspace table:
type(of thing, e.g. item, class, etc.)block id(assigned for workspace purposes, should be integer primary key)concept id(item id fortype='item', class id fortype='class', etc for any categories I add in the future )properties(styling like position and size)
goby-interface/notes.md
[src]
12/18/2025
I’m returning after some busy months to where I left off — no work for the next week and a half, so I’m going to see where I can get with this before the end of the year. Just now I implemented the under_property_max condition that I set up in goby-database on 9/20, thus completing the first bullet from my 9/7 “future tasks” checklist.
Now, I am as usual returning to this with a fresh eye and feeling dissatisfied with the current interface design — specifically, the design of the table rows and cells. I can’t put my finger on it exactly, but here are a few things that are bugging me:
- everything feels a little too spaced out, to the point of being unwieldy. Populating my example table some more may help a little with this, as well as adding the comma-separated display option for selection fields
- I like the general idea of the selection options overlay as a bubble floating by the search field, but I think there needs to be some more satisfying animation when it first appears and as it responds to inputs, and the color styles feel a little bland and flat. These sorts of modals are where I want the interface to feel the most tactile.
The question is whether to continue development in my current lane (moving on to single selects, creating new items from the select menu, and other things listed in the last entry), or go back to design sketching and do another pass at look & feel. Given that I need to do some degree of sketching for single selects anyway, it seems the most efficient to do the latter; that way development will also be more fun when I return to it, because (theoretically) I’ll be more excited about bringing the sketch to life. The cost is obviously that it will slow down progress on the functioning interface, but cultivating a sense of excitement and joy in this project is more important to me than that.
Before I boot up Figma, let me think a little bit about how to proceed here:
- Probably makes sense to browse some references
- Things to explore:
- adding some light texture to the area around the tables
- making the tables more compact, maybe testing a per-table max width and overflow
- (dare I suggest it) other type options? maybe actually utilizing the secondary typeface (fragment)?
- what is the color and texture of overlays/modals? how do I make them contrast with the base content layer and feel more substantial, without feeling completely alien from it (e.g. the selection options overlay need to display options in roughly the same way as they appear in the table cell itself, but the overlay itself needs to feel elevated from the surface it’s on)?
9/7/2025
Some steps left to finish hooking up selection fields with project databases:
- create the ability in goby-database to remove relations (you can only add them right now)
- get the “new item” buttons working
- propagating changes to all the other relations for which they are relevant (as discussed in 9/1 entry)
Future tasks:
- more to do on selection fields:
- in the list of relation options, I need to filter out options in two-sided relationships where the corresponding property in the item has already hit its max values.
- I realize this may read as gibberish — here is an example: A child can have up to two parents. Let’s say in a project representing family trees, I’ve already set Toby’s parents to be Muffy and Gerald. So in the “children” property, Toby should no longer show up as an option
- design and implement different rendering for single-select (max_values=1)
- I’m thinking that if there’s a selected item, it will fade to a low opacity, with the search input overlayed directly on top of it (made clear by the text cursor flashing at the beginning of the field)
- add an X icon to relation option search input to “clear” it
- can be in the position where the bullet point is for the items themselves, so the left alignment matches
- pagination and efficient caching of items
- in the list of relation options, I need to filter out options in two-sided relationships where the corresponding property in the item has already hit its max values.
- other cell types:
- resource and boolean cell display
- saving text changes back to the database
- user-configured styles:
- color palette for classes
- controlled column widths and text/item wrapping
- general functionality and styles:
- gradient on sticky prop header row?
- intuitive tabbing and arrow key navigation
- tabbing should take you down to the same property in the next item
9/1/2025
I’m now in the position I was contemplating in my 6/23/2025 entry, deciding how to handle refreshing the interface after saving changes to the database. I do like the rough approach I thought of there, of writing the changes to the database, and then on the front-end, having all the items that need that info simply fetch what changed for them.
I wonder if when you add an item via the selection dropdown, it will feel disorienting, since the height of the cell will change and the dropdown will get bumped down. One possibility is to instantly set scroll with javascript after that happens to preserve the place of the dropdown in its pre-interacted state.
8/31/2025
I now have a basic select field editing/focus state set up. I spent a lot of time fiddling with the hover states on the various parts of the field: the option search input itself, the already-selected items, and the cell background. I settled for now on not highlighting the latter at all, either when you hover or click into the input, because it feels very heavy and startling, especially for hover. I like the feeling of “editing in place”, without feeling like you’re going into some special editing state/overlay, that you get from this approach, in conjunction with the strategy around focus states that I detailed below.
One other thing I may consider in the future is some sort of cursor indicator, ideally not replacing the cursor itself but just attaching an icon or message to it that gives context to what clicking will do. E.g. if you click on a selected item in a selection field when you have the editor open, you may want it to simply remove the item from the selection instead of “focusing” it.
Next steps are figuring out how to actually retrieve the options for a selection. This is tricky because it involves two factors in conjunction:
- pagination
- filter by label property string match
I won’t have any real cases of pagination to deal with for now, because the scale of my test database is pretty minimal. So I’m inclined to put that aside for now, and just fetch the whole list of options (dynamically, when you open the select input).
But the question is whether to implement the filtering as a back-end part of the item retrieval. I think this will eventually be necessary to get the pagination to function properly.
(realizing just now that two months ago I created a function to handle this retrieval, get_relation_options, though it doesn’t have any string matching consideration)
8/26/2025
Some meditations on focus state (by which I mean a lot more than native input focuses; I’m thinking about all the custom interface elements which have some sort of transitory “editing” state or dialog box, and which typically close out when you interact with something outside of them):
Behavior:
I’m debating about what should happen when you click on another focusable element when you are already focused. Should it:
- immediately focus the next thing
- this is the default behavior of most inputs on the web
- PRO: less friction if you are going between quickly inputs
- CON: reduces ability to escape to a passive/rest state with the mouse
- simply unfocus the current thing, and require you to click again to focus anything else
- this is the behavior of many application input fields
- PRO: preserves the ability to go back to a rest state at any time by clicking anywhere
- CON: creates a lot more friction if someone is moving between fields
I think the challenge with a “table” style presentation is that inputs often fill the entire viewport, so there’s no good place to click “off”. I’m reminded of visiting my father’s office as a child, and playing on the sticky mats installed in door frames to minimize dust in the lab. Using approach #1 on a table would sort of feel like that: wherever you click (step), the page (floor) lightly grabs onto you. Accordingly I think in these sorts of interfaces, developers often opt for approach #2.
However, as a user of other table interfaces, I get really frustrated with the slowness and dissonance that this click-to-exit system creates. It’s like once there’s one thing focused, a forcefield is erected in front of the other interactive elements, and I find myself constantly double clicking to break through it.
So I am inclined towards approach #1. Some ideas to mitigate the “stickiness”:
- offer some kind of universal
close/escbutton, which lives in a corner of the viewport and appears whenever you have something open.- If I do label it
esc, it could also act as a hint/incentive to use the keyboard Escape key to return to the rest state.
- If I do label it
- be a little more conservative with the clickable regions to focus something, e.g. for text strings make the actual text region the clickable part instead of the whole cell with all its white space.
Implementation:
My current approach to tracking focus state (from when I set up text field editing a few months ago) is a store which records relevant identifiers for the element currently focused (e.g. class id, block id, etc and the svelte-generated $props.id() for the component). I’m worried that this will get a little convoluted, and I don’t entirely remember why I took that approach, although I remember agonizing over it a little bit.
Keep it or not though, I think it’s clear what my focus system needs to be able to do:
- record the current item that is focused, so that every item can check whether it is that focusable element can compare itself and display accordingly
- end focus on the currently focused element if someone clicks elsewhere
- (here is the tricky one) accomodate, through one form or another, nested search, so that an element can be focused inside of another focused element
I’d like to achieve all this with the most data and UI-agnostic approach possible.
Maybe what I do is something really absurdly simple and DOM-based:
- utilize
$props.id()to generate element IDs for “focusable” elements - when an element becomes focused, its ID gets added to an array store
- when you focus on a nested element, before adding it, walk up the array store and use
contains()to search for parent-child relationships to each element;- if they exist, keep the parent focused
- if not, remove that from the focused items
- when you focus on a nested element, before adding it, walk up the array store and use
- in any individual component, to check if it’s focused you just search for its ID in the array store.
Yeah this actually sounds pretty good to me. The one thing that concerns me is that if I need any kind of component to keep track of things like whether its parent is focused, the contains() may become a performance issue. Maybe there’s a simple (albeit annoying) workaround like passing a prop called parent_focused down from above.
...or maybe another option is... to not keep track of this globally (lol)? I suppose what I could do is just listen to mousedown events in focused components and decide whether to close them based on whether the thing clicked on is a child element.
7/20/2025
Following up on my thoughts here about the selection field display, what I’d like to set up is two display modes:
- A: listed with the little square “bullets” and no line breaks by default
- B: collapsed into a wrapping list with a fixed width
- undecided on whether it should retain the degree of conventional tag UI that I had in my initial sketches
- coordinately with this, unsure if items should wrap inline-block style or wrap together like a regular comma-separated list
For now, I will focus on A, and not add any max width setting logic. I will also not worry about max height/truncation logic, which may be something I want to look into eventually
And I’d like to explore a mode of interaction that feels more inline:
- rather than opening up a complete edit overlay, the ability to click on individual items to select/remove them
- To add new items, you click on an unpopulated area and it gives you a text field plus a list of options you can select from, which gets filtered as you type. If nothing matches, you can hit enter to just add it as a new item, which then gets added to the corresponding selected class
- it occurs to me that I probably also want some indication of this “linked” action, e.g. a little snackbox that pops up when you do this telling you it’s generated a new item in the corresponding class
6/25/2025
For my future reference, since I’ve had to do it a few times between this project and work: if you’re trying to reduce an array to an object with generic [key:string]:value pairs, you need to do a few things for it to work and for typescript to stop complaining:
- define the param type of the
accumulatorin the callback function to be a generic object. - have the callback function return the
accumulatorobject (I thought this was a typescript thing but it’s occurring to me that this is probably just howreduceworks; it needs the return to track the accumulator across each iteration)
6/23/2025
When it comes time to start writing data from the interface back to the project databases, I think I can use whatever “write” procedure I set up as a centralized hook to re-fetch affected class data. E.g.:
- when relation props are modified, trigger linked classes to re-fetch, either wholesale or limited to columns/rows (or even cells)
- similarly when label text changes, trigger classes that select from it to re-fetch.
6/22/2025
I’m leaving off tonight halfway through implementing the relation property cell display - got pretty far but I’m figuring out my approach to retrieving and caching data as I build this, and there’s a lot more to go than what I have the time to do before bed.
With regard to data: I’m realizing that having the metadata for each class on hand is going to be pretty important, since I need information from these classes to correctly render their items as part of relation property cells. Since this metadata a pretty trivial amount of information, I think it’s okay to serve it up front.
The only part of the database which I think I need to avoid being greedy about is the items, since it’s totally plausible that someone would have a memory-pushing amount of items in their database, and I actively intend to implement pagination. Now this is a misplaced goby-database thought, but I think I should move away from caching these at all on the backend. If I need to do any operation that transforms them, I can ‘stream’ them in a paginated loop without saving them beyond that. And then instead when I retrieve the classes, I can specifically pull the paginated portion that I need for any displayed classes and serve it up.
6/16/2025
As I’m starting to set up the table, one thing that’s becoming clear is I need to figure out how to save and ultimately edit the display state in various ways. Specifically:
- toggle text prop wrapping
- prop column width:
- should it be responsive to the window in some way?
- should it be constrained to a grid?
- what should the default be? I.e. How should it decide the width of columns without any user configuration?
5/3/2025
I did some initial work the other day to set up the retrieval of class data and rendering of the table; ambiently it prompted some ideation on another display style which I think will ultimately be more interesting and useful than the table, and also some dangerous contemplation of the possibility of items which exist in multiple classes. But these are things to explore if/once I can implement this initial vision,i.e. a class of items represented as a table, editable via the diagrammatic property editor interface that I’ve sketched.
The next steps of that implementation are:
- setting up individual components for different kinds of property inputs, e.g. text, single/multiple select, etc, and
- will need to figure out data binding and how to trigger saves to the database/refreshes of data (which as I described earlier, I would like to do more surgically)
- column width and similar workspace display configuration options
- I’m hesitant to implement this before giving more thought to the schema and the specific display settings I want; but the column width thing in particular is just one of those things that is bugging me as a user while I test out the tool; maybe there’s some sort of stopgap solution I can implement for now.
4/27/2025
...on the other hand, if I ever port this so that you can access a project over a network connection, e.g. via an app, I don’t want to be in a situation where goby has to send a bunch of small requests to load anything. So here’s a potential balance to strike: the workspace request can fetch an array of its blocks and an array of item data for each of those blocks. Still TBD whether it also include class item data, or whether that would be a separate request. But possibly it could include the first page of a paginated item set for each class.
4/26/2025
I’m leaning towards loading project data in a distributed way, on a component-level, rather than what I did in the initial implementation, i.e. load everything all at once and reload it all for every change. This will hopefully prevent overfetching data from the database, but it will require me to do some fine-tooth combing when it comes refreshing and propagating the latest data in the interface:
- when a relation prop changes, any items in the targeted classes that changed will have to be re-fetched
- I would ideally want to avoid re-fetching the same asset so that all edits are immediately reactive; e.g. if I have two views of the same class in the same workspace. So I would probably want to centrally record what I’ve fetched as a cache that I pull from and refresh as needed
4/7/2025
I am feeling a little beleaguered after spending many hours this weekend trying to get the electron program to start, amidst challenges with JS module syntax, typescript compilation, and of course the classic mismatch between the node version electron uses and the version for which better-sqlite3 was compiled. But with this push, the thing is finally alive, and hopefully I can begin development in earnest on the interface soon!
4/5/2025
Some steps to get this thing up and running:
- set up a function to open/create a database file and present a blank window
- can keep my original open file dialog for now
- possibly use the sandbox in
goby-databaseto create one of my classic typeface test databases
1/20/2025
Since last touching this repo many things have changed in my tooling + my perspective:
- I’ve refactored/overhauled
goby-databasein a way that likely deprecated some of the back-end code I had set up - Svelte 5 is a thing that I want to use
- Typescript is a thing that I want to use both with svelte and electron
- I’m rethinking my interface dev priorities:
- Instead of with standalone objects, I want to begin with the class interface (as tables, cards, or something else) and more importantly with the class schema editor, which is maybe the most unique and personally interesting aspect of this.
- I don’t know if the idea of a canvas is as important to me as it was? I could totally imagine starting with a basic editor for a single class placed normally in the dom (maybe with the ability to tab between classes).
To all these ends, I’ve done a complete overhaul of the directory structure and run commands, so now I can use typescript, svelte 5 and my update to goby-database are installed, the distribution code is more clearly bundled/isolated, and I’m giving myself a clean slate to get started with interface development again.
Connecting with what I mentioned in the last bullet, I may start by creating a new window type, 'basic', which disregards the workspace parameters I had set out below in the anatomy section.
Anatomy of the interface:
home: where to select a project, and detached window forindexindex: a list of objects, classes, and workspaces in the project- accessible on the
homepage and as a drawer inworkspaces
- accessible on the
workspace: a freeflow canvas for placing elements- object instances
- detached cells with text, images, urls, etc
- tables
- class instances
- other customized table views/class filters
- object instances
hopper: frictionless deposit box for new items
General interface musings:
- I have an idea sketched out/in my mind for a new interface for configuring relation props, relying less on obscure language/iconography and more on physical analogies of drawing connections and wiring circuits
- Possible semantic elements
- circles for classes, diamonds for properties, squares/rectangles for objects
- I’m imagining that this iteration of the interface will be much more stylistically pared back from my previous one, in consideration of the types of interfaces I’m most comfortable working in.
- Possibly less lines
- Models/references:
- IOS Stickies
- Instead of having string versus paragraph cells, maybe I can just have a text cell with an option to wrap or not
- It would make sense / feel nice to me if sorting order isn't saved unless you explicitly save it, and if a sorting reset was easily identifiable/accessible
- In general my current thought is to implement Goby's more unconventional but conceptually important interface features, and otherwise make it as frictionless as possible, and then I can add on settings as I build which are more visually obscured but facillitate advanced usage/presentation modes
- I’m realizing the shift to the “workspace” model for windows clarifies a lot of things, in that by decoupling the styling from the styled class/object, I don't have to worry about things not being displayed, or being artificially constrained in their display. The data for any element is stored with minimal styling information, and then a user decides when, where, and how represent it visually, with that styling information tied to the workspace.
- An "index" drawer accessible through a button in the top-right corner of each page contains everything that exists in the database, and I'm thinking you could drag and drop stuff from it into a workspace.
- This means you could conceivable have multiple instances of an element, for example different instances of a class each filtering its contents or representing it in a visually distinct manner.
- on the development side, this means rather than looping through classes (as in the first iteration), a workspace will loop through each of the elements inside of it to place it.
- With the persistent "index" of items system, it'll have to be clear how and when an item is fully deleted versus merely stashed, and still visible. My thought right now is that items will always delete by default on using the
DELkey, with a contextmenu (right click) option to stash them, whereas classes will be the reverse (stashed by delete key, deleted with right click)
Front-end development:
- It would be ideal to use the same UI elements for both the single select and the multiple select
- Right now I'm using a
storevalue to record the currently “focused” UI element’s ID. But I’m anticipating in the future that there may be multiple focused items at a time, in that you may focus an element inside of the currently focused element (e.g. a search field inside of a dropdown).- To address this, I think the
storevariable will need to be an array, and the unfocus function will need to check when another element is clicked/focused to see if it’s a descendant of any of the focused items in the array. If it’s not, those items need to be unfocused, and if so, then the most recently interacted-with element needs to be added to the array.
- To address this, I think the
- I discovered just now with some playing around in the tutorial that if you bind an undefined variable to a component prop that has defaults, the variable will take on the default value, which is surprising and will hopefully save me some mess.
Home page
- can use recent documents list native to mac and windows to remember what projects have already been opened
- OS window customization
- opening URLs externally https://github.com/electron/electron/issues/1344#issuecomment-208839713
better-sqlite3 misadventures
better-sqlite3 is tricky to combine with electron because it uses the native node installation on your operating system, but to work with Electron it actually needs to use Electron’s internal node version.
Step 1 in addressing that was re-compiling the node-module for Electron’s node version, which you do by following the steps here using electron-rebuild.
- delete
node-modulesandpackage-lock.json - run
npm i - run
./node_modules/.bin/electron-rebuild
However, after resolving that, I started running into an issue with Electron crashing as soon as I ran any commands with better-sqlite3. This turned out to be brand new bug as of writing this, and to fix it the maintainers recommended running
npm install
cd node_modules/better-sqlite3
npx node-gyp rebuild --debug --build-from-source --runtime=electron --target=26.1.0 --dist-url=https://electronjs.org/headers
cd ../..
npm run start
to manually rebuild the module binary, which seems to have worked for me.
This also meant that ultimately I couldn’t just use npm link to install the goby-database code. But instead of just copying it over (which I did last time, ensuing in all sorts of confusions and problems), I just went ahead and published the WIP to npm, and then installed it into the goby-interface repo.
04/2025 update: I had problems pop up with this again after my recent updates to the codebase; I moved to electron version 34.0.0, in which, it turns out, recompiling better-sqlite3 with electron-rebuild produces a monstrous unhandled error and fails. Resolving this is a little beyond me and I couldn’t find any user-documented solutions on github.
Luckily I was at least able to get it running again by reverting to an older version of electron, 28.0.0, in which the rebuild finishes successfully. V28 is also the version in which they fixed the bug mentioned above, so no need to manually recompile anymore.
I’m sure this is not the last time I’ll encounter this issue though — likely it’ll rear its ugly head again when I package the application for distribution.
Ways forward:
text object
- set up click event listener to add tentative text object at the clicked grid coordinate
- figure out how to wire up default item props with the
page_contentsvariable - set up validator upon exiting writing mode to see whether a new item should be added to the db (if it has no id and a length>0) or if an existing item has to be deleted (if it has an id and a length<0)
- set up functions in `goby-database`` to correspondingly add/remove items and set their values
- this should be called from
itemwith a debouncer so it only updates the db when it's reasonably clear you're done typing
- set up
TextCellcomponent usingtextarea, with wrapping controls- set up hitting
shift+enterorescor clicking elsewhere to exit writing mode
- set up hitting
drag selection
- detect when blocks/class rows are in the selection rectangle and add them to the selection
- make the rectangle persistent if it doesn't encounter any blocks, and provide options to fill region with a text or image item
contextmenu
- set up event dispatcher signaling that an action has been clicked on in the menu
- make it appear on the left side of the mouse if the menu would go over the page edge
set up right-click "context menu" dialog with options to create a class or add an image
set up class creation, which should involve placing the circle+line and giving the class a name (which is validated to make sure it’s unique)
continue considering the mechanics of different interactions, particularly the creation and modification of relation properties
*occasionally outdated/bypassed
goby feature repository
[src]
9/10/2023
Opening a multiple select field as its own isolated “block” on the canvas
8/23/2023
Complete index:
A list of all workspaces, classes, and freestanding objects. Classes would be accordions (possibly using <summary>/<details>), so upon clicking on them you would be able to see their constituent objects.
I’m imagining this to be accessible from the home tab once a project is open, and possibly also as some kind of drawer nav in all workspaces.
8/23/2023
Single table workspaces/windows
I’m thinking of my fondness of the Stickies app on MacOS (where I’m currently drafting this), and the way it isolates notes in different window contexts. I think it would be nice if Goby had a similar functionality, possibly with a responsive column width (while still keeping the widths in grid square units). I’m also realizing that developers have access to the “float on top” window type on MacOS, so I could add that as an option.
8/23/2023
Visual joins:
In the same way that you can join tables in SQLite on a shared column, I think it would be cool if you could visually link up two or more classes using their relation properties, possibly separating multiple choice selections into multiple rows and only showing repeated information once. I could imagine how the header for a table could be augmented to represent that:
● Typefaces + ● Foundries on ⬩Foundry/⬩Created
8/20/2023
Matrix view:
Ability to create a matrix table representation of two classes intersected in their relations with a third, e.g. in a table displaying political candidate positions by issue, made using the intersection of a candidates table and issues table on a position table
goby moods
[src]
@alecwestworld12/24/2025
Destiny UI Reel12/19/2025
giphy.gif12/19/2025
Super Metroid Developer's Map8/1/2025
imaginary use cases
[src]
8/5/2022
meal planning
I'm envisioning a list of meals typified by cooking complexity, recipe, leftover friendliness, nutrition rating, etc., and then related to their various raw ingredients, so you could apply a filter limiting the result to what you can make with what you currently have at home. (Bonus, doubles as a running shopping list.)
8/2/2022
keeping different assets related to a project organized within a single documentation space
Right now with Goby I create a separate channel whenever I have a specific category of note which I want to write, e.g. dev notes, future features, use cases. Instead with goby, I could simply keep all these notes in one place and separate them by tables with different fields.
8/2/2022
planning a paper
The paper that I’m currently working on is giving me a moment of “gee I wish Goby was built-out enough to use for this”, so I’m going to record the use-case so I can keep it in mind when I’m in the weeds of working on the interface later on:
I have just gotten finished reading a collection of texts by different authors. The exercise has left me feeling ready to generate a list of “themes” which serve several purposes:
- they allow me to find patterns between the texts: different ways in which the same idea or problem is being articulated, and which I could use my paper to compare
- they allow me to group passages and quotes that I can draw upon while writing, some of which belong to multiple themes. This gives me an impetus to revisit each text as well.
- they can be related with one another, so I have a more holistic view of my topic and how different lines of argument support one another
- they can be related back to the authors, so I can get a sense of how their worldviews stand in relation to one another
This is a mapping task too complex to be done, at least in a conveniently and orderly fashion, using a simple tagging or mind-mapping tool.
Ironically the subject of the paper is in part the idea that you can’t perfectly crystallize ideas in representative logical relations, as I seem to be advocating here. But I have never seen Goby as a project of accurately representing reality; rather, the act of ordering ideas and assets in this way is a pathway, a “disposable ladder” if you will, to greater and clearer understanding.
8/2/2022
dev log
Making Goby dev notes channel and realizing it would be useful to be able to enter bugs and future features with fields for task type, screenshots, front end v. back end, and what other entries it depends on.